上回说了,全赞AI的应用里面有用到几十个大模型,我的其他的应用比如渣渣句,熊喵表情都会或多或少的用到一到两个大模型的推理。而众所周知,目前大模型的推理存在两个问题,一个是慢,一个是贵,慢的问题基本有赖于模型自身结构的优化才能从根本上解决,我暂时未研究这一块的内容,以后看看是否有推理框架能对大模型进行推理加速。本文主要讲一讲大模型推理成本的优化。
推理成本说的简单点,就是用户用你的大模型画一张图,你要花多少钱。这个怎么优化?我首先想到的是“自建机房”的思路,就是用自己闲置的带GPU的游戏主机,来搭个简易的推理集群,如下图所示。
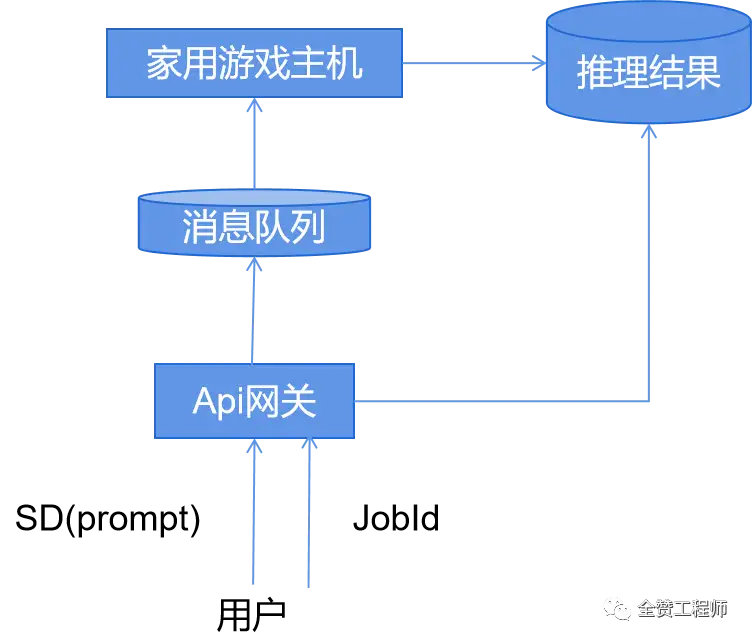
家用主机是没有公网IP的,所以在Api网关和家用主机之间只能靠消息队列进行通信,这里如果有多台家用主机也没有关系,所有的游戏机都可以监听消息队列,然后率先拿到任务的机器来处理任务。这样用户用的请求就变成异步的了,用户第一次请求,只是告诉了系统,我需要文生图,然后系统返回给用户一个任务ID,接下来,用户需要每隔1秒钟拿着这个ID去询问我这个图画好了没有,直到家用游戏主机真正的把图画好之后才结束。
这个架构我也在线上跑了几个月,各种不适,主要是物理上的断电,机器太吵之类的,后来这个机器干脆自己冒白烟了,我赶紧把这个服务器停了。换成了下面这种看起来复杂很多的方案。
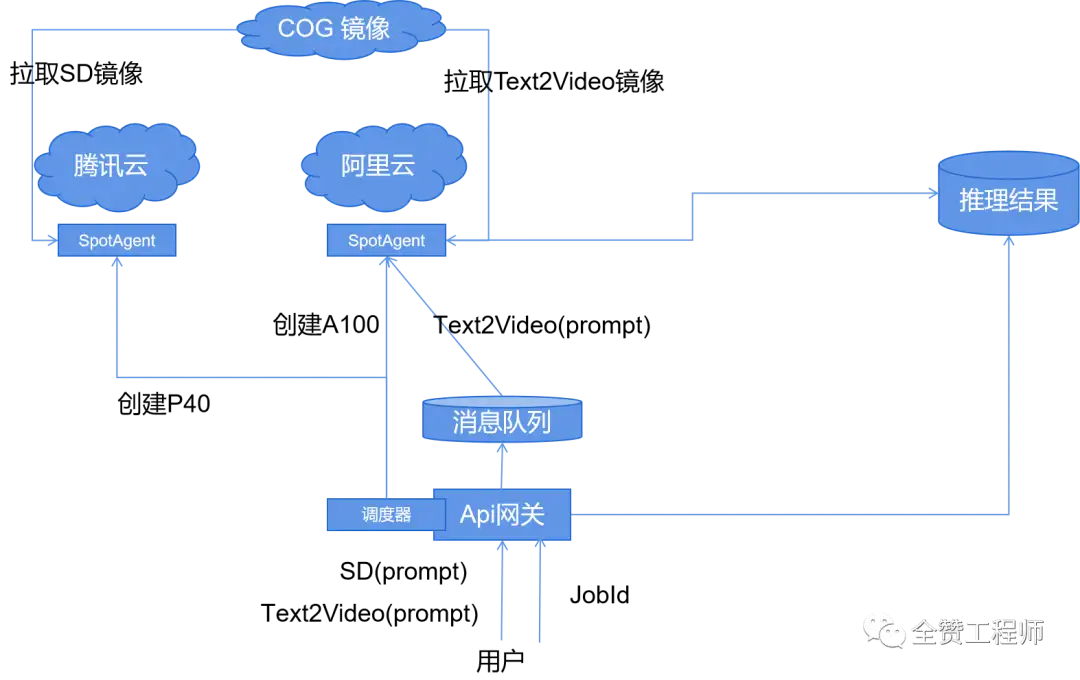
这个方案比较巧妙的地方是使用了各大云厂商的竞价实例来降低成本,并且能规模化,不管你后端用到多少个大模型,都可以用极低的价格搞定推理的事情。
- 首先我研发了一个调度器,它的功能就是根据用户的推理请求,分配相应规格的机器,比如用户说我要生成视频,调度器一查表,这个任务需要A100,然后再一查分配现状,发现没有A100在线上,那么需要找大厂调度了,于是用大厂的API问一下价格(标注上我只要竞价实例),发现腾讯现在没有A100的竞价实例,阿里的A100只要2元/小时,于是果断的对阿里说,这个A100我要了,开一个小时先。
- 得先在腾讯云和阿里云,华为云等各大厂商那里安排一个驻场的(SpotAgent),这就是一个云服务器启动模板,一旦调度器发请求给阿里云,这个SpotAgent就会起起来。阿里云的SpotAgent起来后会监听消息队列,它发现有个任务是文生视频,于是它果断的去拉取文生视频的镜像下来开始做推理。
- 不得不提一下COG,replicate/cog: Containers for machine learning (http://github.com),这个是专为机器学习模型开发的容器,它让所有的模型都能被标准化的安装,标准化的推理。
- 用户还是老样子,先发请求拿到个任务ID,但是第一个用户要忍受冷启动的问题(5分钟),然后不停的轮询他的任务做完没有。
这个计算架构能节省50%-80%之多的GPU账单,可能我这儿一公开,大厂的竞价实例GPU要卖断货了。我最近还在想如何用户自己的GPU做我们的推理服务器,如果这个事情能做成,并且能规模化,那大模型真的就可以做到免费了。
Comments are closed